Learning objectives: Estimate the mean, variance, and standard deviation using sample data. Explain the difference between a population moment and a sample moment. Distinguish between an estimator and an estimate. Describe the bias of an estimator and explain what the bias measures.
Questions:
20.11.1. During a recent workweek, Peter recorded the number of dropped calls to the company's support line. For the tiny sample of five days (n = 5), the average number of dropped calls was 9.60 per day. Peter used Excel's VAR.P() to retrieve the variance and the result was 1.840. However, his colleague Mary pointed out that this is a biased estimate of the unknown population variance. What is the unbiased estimate of the variance?
a. 1.472
b. 1.840
c. 2.300
d. Needs more information.
20.11.2. To compute the daily mean return of a portfolio over the last month that contained 21 trading days, Barbara divides the summation (i.e., of the 21 daily returns) by 20 because 20 equals (n-1) and her sample mean estimator is given by ΣX(i)/(n-1) rather than ΣX(i)/n. Her colleague Derek says that her version of the sample mean is biased. But Barbara points out the following fact: as the sample size increases (i.e., as n ⟶ ∞), she expects her version of the sample mean estimator to converge toward the true population mean. Barbara says that this proves her estimator is unbiased. Is Barbara correct that her version of the sample mean estimator is unbiased (which of the following statements is TRUE)?
a. No, she is incorrect because her sample mean estimator is consistent but biased
b. No, she is incorrect because the central limit theorem (CLT) requires a large sample
c. Yes, she is correct because an estimator is unbiased if its expected value approaches the population's parameter (in this case, the mean) as the sample size increases
d. Yes, she is correct because the unbiased sample variance divides by (n-1) rather than (n) and, to be consistent, so should the sample mean
20.11.3. Barbara and Peter were both given the same set of daily returns for a volatile asset over the last two weeks (n = 10 trading days). See below. Their assignment was to estimate unknown population parameters by calculating sample moments (we are using sample variance and sample standard deviation interchangeably: the second central moment is the variance, and its square root is a standard deviation). On the theory there exists a "true" population mean and daily standard deviation (aka, volatility) for the asset, they each computed two statistics:
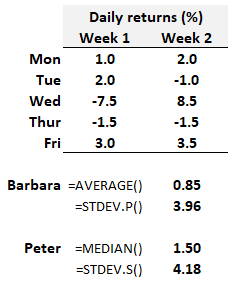
We can see from the exhibit above that:
a. Barbara is wrong (i.e., she made a mistake) because her 3.96% is an estimator rather than an estimate
b. Peter is wrong (i.e., he made a mistake) because the median is an estimate, but the median is not an estimator
c. Either Barbara or Peter must be wrong: if they were each given the exact same dataset, they must compute the same sample standard deviation (aka, sample volatility)
d. Both are correct (i.e., neither is wrong) because they each used different but valid estimators of both the population mean and population standard deviation
Answers here:
Questions:
20.11.1. During a recent workweek, Peter recorded the number of dropped calls to the company's support line. For the tiny sample of five days (n = 5), the average number of dropped calls was 9.60 per day. Peter used Excel's VAR.P() to retrieve the variance and the result was 1.840. However, his colleague Mary pointed out that this is a biased estimate of the unknown population variance. What is the unbiased estimate of the variance?
a. 1.472
b. 1.840
c. 2.300
d. Needs more information.
20.11.2. To compute the daily mean return of a portfolio over the last month that contained 21 trading days, Barbara divides the summation (i.e., of the 21 daily returns) by 20 because 20 equals (n-1) and her sample mean estimator is given by ΣX(i)/(n-1) rather than ΣX(i)/n. Her colleague Derek says that her version of the sample mean is biased. But Barbara points out the following fact: as the sample size increases (i.e., as n ⟶ ∞), she expects her version of the sample mean estimator to converge toward the true population mean. Barbara says that this proves her estimator is unbiased. Is Barbara correct that her version of the sample mean estimator is unbiased (which of the following statements is TRUE)?
a. No, she is incorrect because her sample mean estimator is consistent but biased
b. No, she is incorrect because the central limit theorem (CLT) requires a large sample
c. Yes, she is correct because an estimator is unbiased if its expected value approaches the population's parameter (in this case, the mean) as the sample size increases
d. Yes, she is correct because the unbiased sample variance divides by (n-1) rather than (n) and, to be consistent, so should the sample mean
20.11.3. Barbara and Peter were both given the same set of daily returns for a volatile asset over the last two weeks (n = 10 trading days). See below. Their assignment was to estimate unknown population parameters by calculating sample moments (we are using sample variance and sample standard deviation interchangeably: the second central moment is the variance, and its square root is a standard deviation). On the theory there exists a "true" population mean and daily standard deviation (aka, volatility) for the asset, they each computed two statistics:
We can see from the exhibit above that:
- Barbara calculates a mean (average) daily return of +0.85% with sample volatility of 3.96%
- Peter calculates a median daily return of +1.50% with sample volatility of 4.18%
a. Barbara is wrong (i.e., she made a mistake) because her 3.96% is an estimator rather than an estimate
b. Peter is wrong (i.e., he made a mistake) because the median is an estimate, but the median is not an estimator
c. Either Barbara or Peter must be wrong: if they were each given the exact same dataset, they must compute the same sample standard deviation (aka, sample volatility)
d. Both are correct (i.e., neither is wrong) because they each used different but valid estimators of both the population mean and population standard deviation
Answers here: