RiskNoob
Active Member
Hi David,
Could you help me out to clarify the basic backtesting? From the last sentence in page 61 in BT notes (Jorion Ch6, Backtesting VaR), it says:
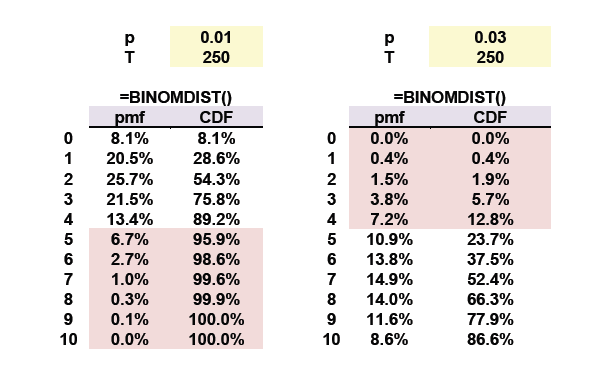
“…In the case of an incorrect model (below right; 3%), the probability of a Type II error is 12.8%”
If the t-statistics from given sample exceed the critical-value (falls into the red-region, 12.8%) in the binomial distribution, the null hypothesis is rejected. and I think this is a ‘good’ decision since the model (null hypothesis) is indeed not correct.
So in my opinion the above sentence could be re-phrased something like:
“…In the case of an incorrect model (below right; 3%), the probability of a NOT making Type II error is at least 12.8%” (it is because Type II error is hard to derive – e.g. failed to reject when the statistics does not exceed the critical value)
Furthermore, the hypothesis test is two-sided, but it is a bit unclear whether it is a two-tailed from the histogram in the notes (same thing can be observed in Jorion’s histogram 6.2) – but it might be due to the binomial distribution which is not continuous.
RiskNoob
Could you help me out to clarify the basic backtesting? From the last sentence in page 61 in BT notes (Jorion Ch6, Backtesting VaR), it says:
“…In the case of an incorrect model (below right; 3%), the probability of a Type II error is 12.8%”
If the t-statistics from given sample exceed the critical-value (falls into the red-region, 12.8%) in the binomial distribution, the null hypothesis is rejected. and I think this is a ‘good’ decision since the model (null hypothesis) is indeed not correct.
So in my opinion the above sentence could be re-phrased something like:
“…In the case of an incorrect model (below right; 3%), the probability of a NOT making Type II error is at least 12.8%” (it is because Type II error is hard to derive – e.g. failed to reject when the statistics does not exceed the critical value)
Furthermore, the hypothesis test is two-sided, but it is a bit unclear whether it is a two-tailed from the histogram in the notes (same thing can be observed in Jorion’s histogram 6.2) – but it might be due to the binomial distribution which is not continuous.
RiskNoob


 . We might be tempted to increase the cutoff to 5, which lowers the Prob of a Type I error to 4.12% (yay!), but then if the bad model is 97% (which ain't too bad really!) we increase the Prob of Type II error to fully 23.73%. I hope that explains!
. We might be tempted to increase the cutoff to 5, which lowers the Prob of a Type I error to 4.12% (yay!), but then if the bad model is 97% (which ain't too bad really!) we increase the Prob of Type II error to fully 23.73%. I hope that explains!